背景
介绍如何实现四层协议(TCP层)的负载均衡功能,及可能遇到的问题。
简单组网
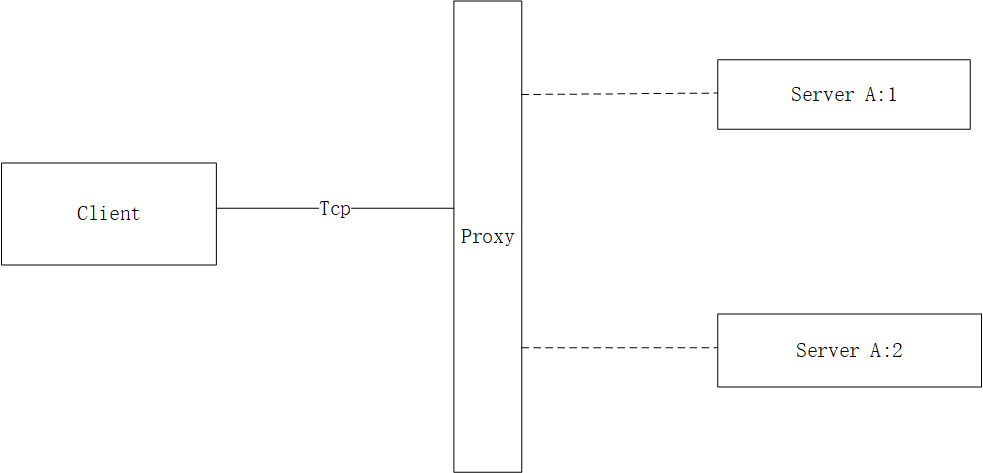
当客户端经过中间代理proxy(lvs/nginx)通过四层转发时,client就会和A:1(或A:2)建立长链接,一旦建立之后client的请求都会走固定好的长链接。这里有几个点说明下:。
在A异常时需要重新进行三次握手,那么在握手期间client–>A的消息将会被丢失;
由于固定了长链接,所以client的请求都只会到A:1 ,无法做到请求均衡;
如果Proxy感知到A:1异常,那么client的就会和A:2建立长链接,做到了容错的功能;
虽然我们可能会存在多个client,这样通过proxy的hash算法能够做到链接均衡,但是当服务A:1 异常一段时间后仍没有恢复工作时,那么大量的链接都会压到A:2 中,这样会导致A:2 压力过大;同时在重连时消息会丢失
nginx的热升级功能
保证nginx在不停止服务的情况下更换他的 binary 文件,那他是如何实现的呢?
其实研究他的原理,你会发现,所谓的“不停止服务”是针对http协议,在进程中同时保留old和new进程,之前的请求在old中进行,新的请求在new中进行,并进行慢慢的迁移。所以对于四层协议,nginx也是做不到的。长链接没有所谓的黑科技。
方案
我们采用的方案是客户端启动n个链接(默认4个),如下
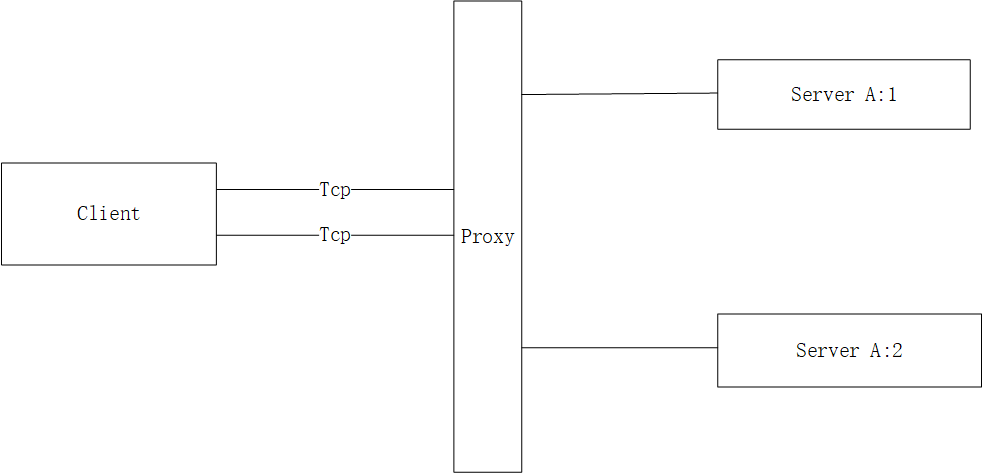
然后代理通过轮询的方式,所以client 其实是和A:1、A:2 同时建立了tcp链接,client在发送请求时通过轮询的方式给各个tcp链接进行发送,这样基本能做到
握手时消息不丢失
请求的均衡
容错
这种方案也存在如下问题:
也存在无法分担流量问题
比如A:1 异常后没有快速恢复(恢复的时间由proxy的保活时间决定),那么client的所有链接仍然会落到A:2 上,当A:1 恢复时,无法分担流量1
2这个问题就需要引入服务发现和服务治理的功能;当A:1 恢复时自动触发client的重连;
或者简单点手动对client进行tcp重连(目前做法)
通知功能丢失
使用tcp的一个重要目的是支持全双工能力,比如当有个下游B服务,需要发送通知给client,client能够主动感知到。 那么架构设计如下:
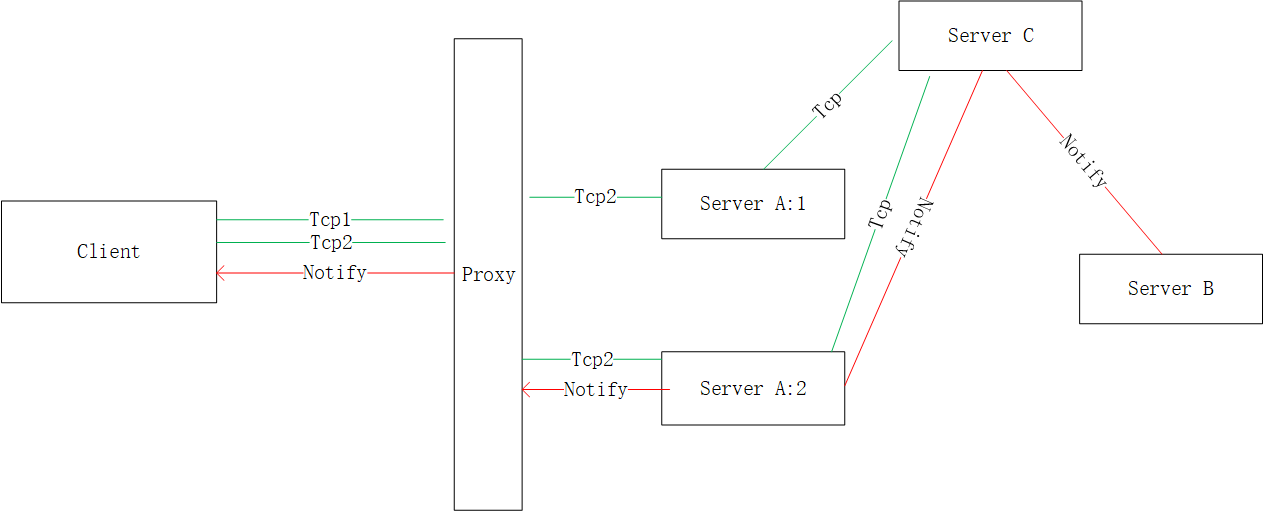
client通过tcp链接到服务A之后,服务A会登记信息到服务C, 我们一般采用覆盖的方式记录,比如在服务C中,只记录 client—->A:2 这条路径(即使client 也同时和A:1有链接); 以后其他任何服务需要发送通知给client时,只要发送消息给服务C即可,就是图上红色线的notify路径。
我们分析下存在的问题:
A:1 服务出现异常,tcp1将进行tcp重连,如果A:1能快速恢复,继续和A:1进行连接,如果不能快速恢复那么就和A:2 重连;之间因为tcp:2 连接并没有断开,所以client到A的任何请求仍然正常; B的notify消息也能转发给client; 没问题
A:2 服务出现异常,tcp2将进行tcp重连,之间因为tcp:1 连接并没有断开,所以client到A的任何请求仍然正常;但是再没有重连成功前B的通知消息将无法正常。
比如解决方法:
C中登记client和A:1、A:2 的所有路径,然后再转发时判断哪个A和C正常链接就使用哪个。
这样也会引入其他问题: C中client记录的会逐步变多,所以要维护好这个链表需要引入一些淘汰功能;
同样的,A:2和C链接正常并不代表client和A2链接正常,所以也同样存在可能B无法发送通知给client的问题。
……
思来想去,对于这个问题的完美解决必然会引入更多的流程,所以这个问题就留着吧,作为暂时的设计缺陷。

