背景
准备换一个公司,所以想把自己最近几年一些东西进行一次总结。
工作背景介绍
我是在一家中小游戏公司负责游戏大厅相关服务的开发和维护,主要就是负责用户登陆、登出、消息通知、充值、活动、找人、聊天、战绩结算等等和游戏业务无关的工作。 虽然和具体游戏没有关系,但是所有的游戏又依赖这个大厅服务,所以算是公司核心团队; 同时我也负责中间件的开发,比如redis库、mq库、日志库、通讯库、预警库……的开发。 好了,大概就是这些内容。
项目初期
我刚来时,大厅服务已经有人维护,但接触一段时间下来,遇到一些不好的地方。
开发工具落后
没有持续集成
升级麻烦
异常定位手段落后
服务异常无法预警
开发工具落后
仍然使用的是vc6.0开发工具,导致新的语法无法使用。 花了不少时间把开发工具升级到vs2013,之间也碰到一些bug,比如有些字符串大小写转换时vc6是不会报异常,但是vs2013就会抛出异常。
没有持续集成
引入jenkins
升级麻烦
服务的升级都要在凌晨6:00玩家最少的时候升级,而且升级时开发人员也需要在线,有时候需求多的时候,经常要这么早起床;
升级对玩家数据有影响,因为大部分服务的数据是放置在内存中,导致重启后数据丢失,玩家不得不重新登陆;同时有些上下游服务都有依赖,有部分服务升级之后,要到下午玩家反馈才知道数据错误,很被动。
- 架构调整
1 | 业务接口进行合并、分拆到不同服务中; |
- 无内存设计
1 | 并非真的无内存,只是内存数据 1)持久化 2)缓存淘汰。 重启服务内存丢失对业务0影响。 |
- 配置中心
1 | 引入携程的apollo,优点是使用简单、丰富的权限管理、配置回滚等等完善的功能;使用不错。 |
- 客户端负载均衡
1 | 服务器都是用tcp开发,所以在引入负载均衡中间件(nginx、lvs)同时,也需要依赖客户端的负载均衡。各个服务端之间相连会使用4个tcp链接,这样一部分上游服务重启期间,通讯仍然能够正常。 |
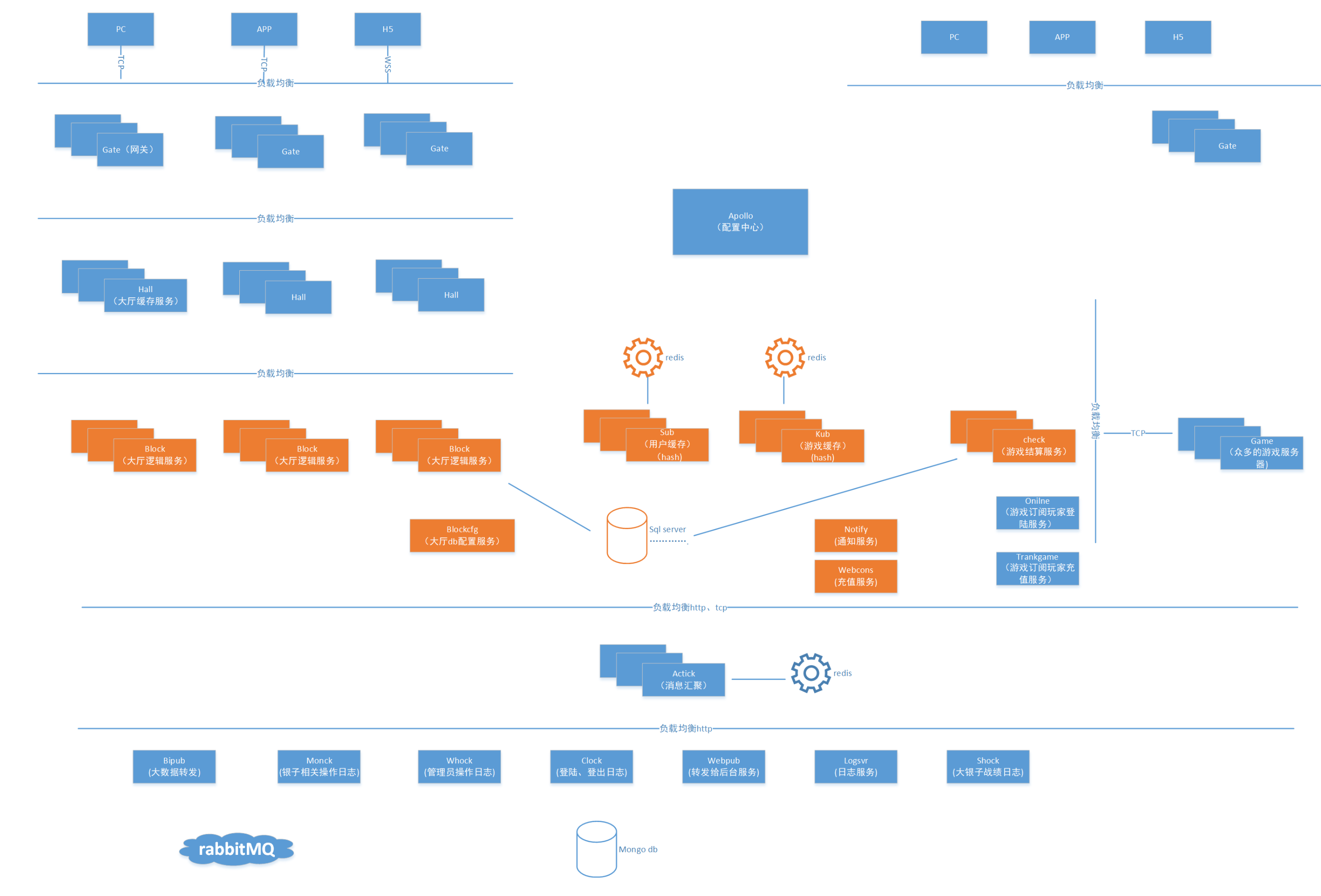
经过如上的一些改造,现在除了网关服务重启客户端有感知外,其它服务任何时间点重启玩家业务都不受影响;对于重大特性的升级,还可以通过蓝绿升级的方式进行逐步升级。
定位手段落后
之前异常出现时,不怎么会用dump分析,都是通过远程调试,影响线上环境。
服务程序增加异常crash库,当出现异常时自动保存dump、异常上下文,并发送钉钉告警,快速就可以定位到异常点;
进行windbg经典案例分享,让同事掌握分析异常三板斧。
服务异常无法预警
没有预计功能,服务出现异常时,只能被动的等待玩家反馈;同时也没有预计机制,当程序有异常征兆时无法扼杀。
改进方式:1
2
3
4
5
6
7熟悉通讯库模型: 多生产者---多消费者模型。 套接字上报的报文会转发到唯一的消息队列,多消费者线程通过竞争模式从消息队列中获取数据。
当消费者线程出现死锁、性能低等等情况导致无法及时消费时,消息队列报文会逐步上升;
所以按照这个特性,增加agent线程,每5s钟上报消息队列数量、进程句柄、进程线程数、进程内存、进程cpu等信息给elk系统,然后通过kibana进行报表显示;对于消息堆积数大于阈值(300)、或重启时则直接进行钉钉告警。
这样就有效的进行了程序的预警。
1 | 定时上报进程信息到elk,也非常有利于后续问题的定位,比如可以查看历史的内存信息、历史的句柄信息等。 |
结论
目前大厅同时在线人数30w,支持100w是没有任何问题的;如果到200w+,那么里面有些中间件就需要考虑集群的方式;500w+估计还要重构一把,再多玩家就没考虑过了……
虽然离微服务还有距离,但也成功的解决了历史的痛点,线上稳定性在99.9%,发布、问题定位都还算方便,后续慢慢会淘汰一些陈旧的运维工具,使用成熟的技术实现微服务的一些功能:比如服务发现、服务治理、服务定义等等。
最终的效果就是: 原来团队5人维护,现在只有1人维护,自己把自己搞失业了(开玩笑) 😓…………

