背景
当出现问题时,我们收集无法查看历史的进程信息,比如前一小时的cpu利用率、内存使用量等信息。
本方案结合大数据的elk系统提供可视化的报表数据。
elk = Elasticsearch Logstash Kibana 搭建一套集中式日志系统。
每个进程定时5s上报进程状态到elk系统,然后通过kibana进行报表输出。
状态上报协议
udp + json
每个进程接入组件后,组件会定时启动一个线程以5s间隔上报进程状态,通过udp协议,json负载的格式。
采集方式
使用windows性能计数器api:
API介绍:
1、PdhOpenQuery:获取性能监视器数据查询句柄;
2、PdhAddCounter:添加计数器;
3、PdhCollectQueryData:查询性能监视器数据;
4、PdhGetFormattedCounterValue:获取指定计数器数值;
参考代码:
进程关键状态信息
进程已处理消息数
作为后台服务器,通过该数值可以评估该台服务器的负载
进程消息队列堆积数
服务器采用生产、竞争消费模式设计,当消费线程无法处理时,生产队列会发生堆积,所以需要定时上报生产者队列当前数量,已评估服务器是否正常。 比如堆积 >300 时,钉钉警告 ; > 1000 并持续上涨时,需及时进行问题分析
进程cpu
1 | pdh: \\Process("calc")\\% Processor Time |
建议值80以内。
获取的是该进程在单核下的cpu值。
进程handle count
1 | pdh: \\Process("calc")\\Handle Count |
内核对象数量。如果程序稳定,handle应该维持在一个稳定区间,持续上涨说明存在handle leak
进程提交内存
1 | pdh: \\Process("calc")\\Private Bytes |
提交内存,如果持续上涨,说明存在 memory leak
进程虚拟内存(保留空间)
1 | pdh: \\Process("calc")\\Virtual Bytes |
保留内存,vitrual bytes 和 private byte 一般保持一个相对稳定的比例关系。
大Virtual size(比如1.0G)时如果他们的比例大于 >2 时,需要考虑是否存在严重的内存碎片,仅参考意义
进程ID
1 | pdh: \\Process("calc")\\ID Process |
进程id号,如果发生变化则说明服务存在重启
进程客户端数量
统计服务器当前tcp的连接数
进程的磁盘空间
其他进程日志导致磁盘满,导致服务异常, 当磁盘空间<1.0G时上报告警
和钉钉对接
状态的上报只解决了历史的信息查询,对于当前紧急问题需要及时通知到钉钉群。
elk 系统和告警中心进行对接
负载中的json中携带 “level” 字段,当 = “warn” 时elk转发消息给告警中心,告警中心处理钉钉消息
组件直接发送钉钉
通过json中的 “level” = “warn” 时,组件直接发送告警信息到指定钉钉群
kibana报表
自己是报表白痴,所以操作方式自己作为笔记写下来:1
2
3
4
5
6
7visualize
选择“line”
选择“hallgame”(自定义的)过滤器
Metrics 的Y-Axis 选择“Max”, Field 选择”tcCpu”(举例),lable 填写 "cpu利用率"
Buckets 的X-Axis 选择”Data Histogram“
Buchets 的Split Series 选择”terms“,Filed 选择"svraddr"(代表不同的进程), order by 默认(指得是排序),size 填20均可
然后运行,就可以看到所有服务的 cpu利用率了。
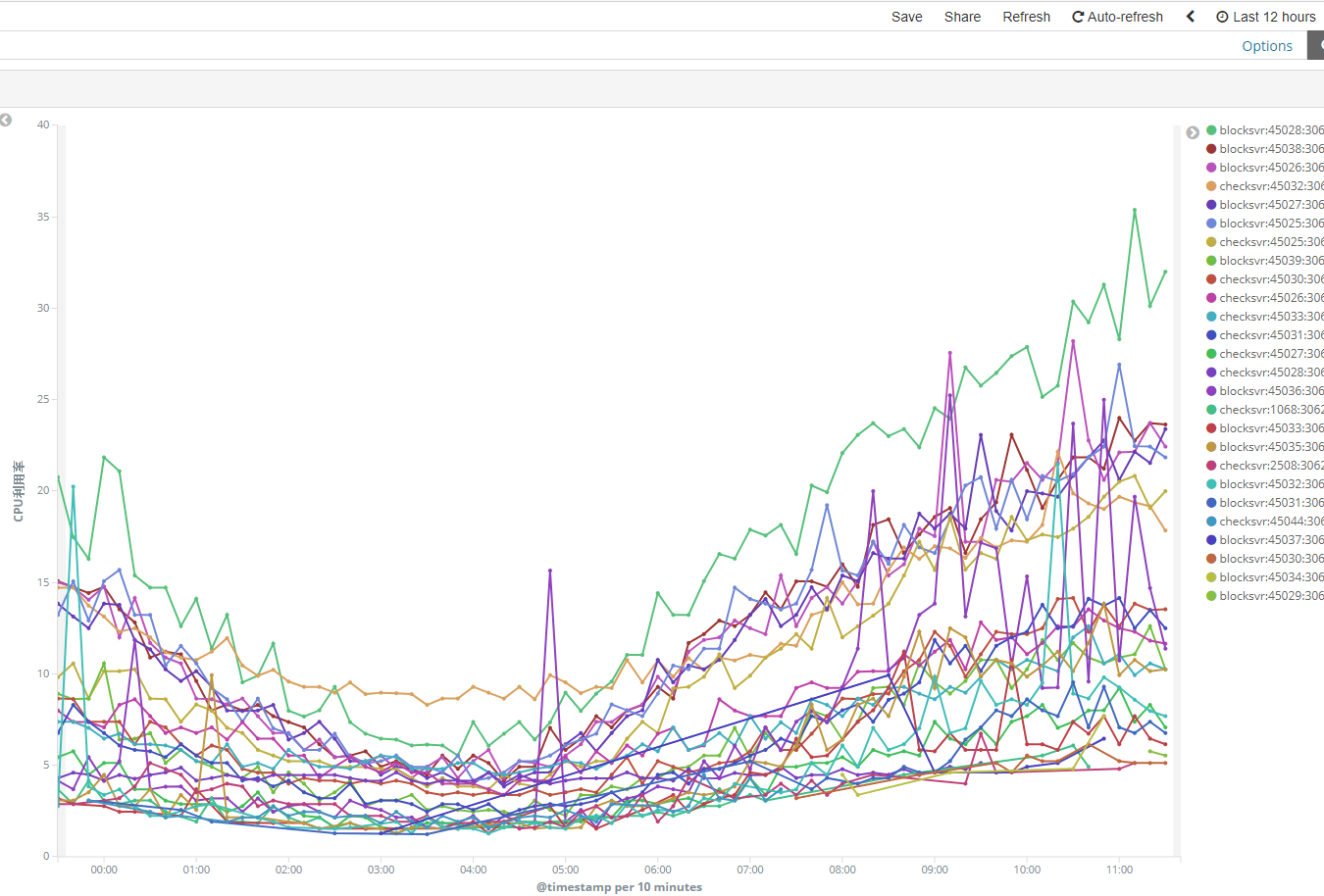
效果
在kibana中配置报表消息,可看到如下效果: